

Agentic Engineering Patterns >
There are some behaviors that are anti-patterns in our weird new world of agentic engineering.
Inflicting unreviewed code on collaborators
This anti-pattern is common and deeply frustrating.
Don't file pull requests with code you haven't reviewed yourself.
If you open a PR with hundreds (or thousands) of lines of code that an agent produced for you, and you haven't done the work to ensure that code is functional yourself, you are delegating the actual work to other people.
They could have prompted an agent themselves. What value are you even providing?
If you put code up for review you need to be confident that it's ready for other people to spend their time on it. The initial review pass is your responsibility, not something you should farm out to others.
A good agentic engineering pull request has the following characteristics:
- The code works, and you are confident that it works. Your job is to deliver code that works.
- The change is small enough to be reviewed efficiently without inflicting too much additional cognitive load on the reviewer. Several small PRs beats one big one, and splitting code into separate commits is easy with a coding agent to do the Git finagling for you.
- The PR includes additional context to help explain the change. What's the higher level goal that the change serves? Linking to relevant issues or specifications is useful here.
- Agents write convincing looking pull request descriptions. You need to review these too! It's rude to expect someone else to read text that you haven't read and validated yourself.
Given how easy it is to dump unreviewed code on other people, I recommend including some form of evidence that you've put that extra work in yourself. Notes on how you manually tested it, comments on specific implementation choices or even screenshots and video of the feature working go a long way to demonstrating that a reviewer's time will not be wasted digging into the details.
Tags: ai, llms, ai-ethics, coding-agents, ai-assisted-programming, generative-ai, agentic-engineering, code-review
It’s not slop because it was created by an AI. It’s slop because it’s slop.
I just read the first two pages of a sci-fi novel on my Kindle. The author proudly proclaims that the 400-page book was created without any AI whatsoever. Alas, the book is slop. The writing is overwrought and the dialogue is banal. If a page isn’t worth writing, it’s unlikely a chapter is.
Slop happens when a marketer who should know better stops trying. It’s when we prioritize volume over impact. If we measure the cost of what we create instead of its value, it’s likely we’ll end up with slop.
AI makes this easier, no doubt. But it pays to focus on avoiding slop, not in worrying how the slop is made.
The question is now, “Who approved this?” not “who made this?”
I have written eight of these guides since ChatGPT came out, but this version represents a very large break with the past, because what it means to “use AI” has changed dramatically. Until a few months ago, for the vast majority of people, “using AI” meant talking to a chatbot in a back-and-forth conversation. But over the past few months, it has become practical to use AI as an agent: you can assign them to a task and they do them, using tools as appropriate. Because of this change, you have to consider three things when deciding what AI to use: Models, Apps, and Harnesses.

Models are the underlying AI brains, and the big three are GPT-5.2/5.3, Claude Opus 4.6, and Gemini 3 Pro (the companies are releasing new models much more rapidly than the past, so version numbers may change in the coming weeks). These are what determine how smart the system is, how well it reasons, how good it is at writing or coding or analyzing a spreadsheet, and how well it can see images or create them. Models are what the benchmarks measure and what the AI companies race to improve. When people say “Claude is better at writing” or “ChatGPT is better at math,” they’re talking about models.
Apps are the products you actually use to talk to a model, and which let models do real work for you. The most common app is the website for each of these models: chatgpt.com, claude.ai, gemini.google.com (or else their equivalent application on your phone). Increasingly, there are other apps made by each of these AI companies as well, including coding tools like OpenAI Codex or Claude Code, and desktop tools like Claude Cowork.
Harnesses are what let the power of AI models do real work, like a horse harness takes the raw power of the horse and lets it pull a cart or plow. A harness is a system that lets the AI use tools, take actions, and complete multi-step tasks on its own. Apps come with a harness. Claude on the website has a harness that lets Claude 4.6 Opus do web searches and write code but also has instructions about how to approach various problems like creating spreadsheets or doing graphic design work. Claude Code has an even more extensive harness: it gives Claude 4.6 Opus a virtual computer, a web browser, a code terminal, and the ability to string these together to actually do stuff like researching, building, and testing your new website from scratch. Manus (recently acquired by Meta) was essentially a standalone harness that could wrap around multiple models. OpenClaw, which made big news recently, is mostly a harness that allows you to use any AI model locally on your computer.
Until recently, you didn’t have to know this. The model was the product, the app was the website, and the harness was minimal. You typed, it responded, you typed again. Now the same model can behave very differently depending on what harness it’s operating in. Claude Opus 4.6 talking to you in a chat window is a very different experience from Claude Opus 4.6 operating inside Claude Code, autonomously writing and testing software for hours at a stretch. GPT-5.2 answering a question is a very different experience from GPT-5.2 Thinking navigating websites and building you a slide deck.
It means that the question “which AI should I use?” has gotten harder to answer, because the answer now depends on what you’re trying to do with it. So let me walk through the landscape.
The Models Right Now
The top models are remarkably close in overall capability and are generally “smarter” and make fewer errors than ever. But, if you want to use an advanced AI seriously, you’ll need to pay at least $20 a month (though some areas of the world have alternate plans that charge less). Those $20 get you two things: a choice of which model to use and the ability to use the more advanced frontier models and apps. I wish I could tell you the free models currently available are as good as the paid models, but they are not. The free models are all optimized for chat, rather than accuracy, so they are very fast and often more fun to talk to, but much less accurate and capable. Often, when someone posts an example of an AI doing something stupid, it is because they are either using the free models or because they have not selected a smarter model to work with.
The big three frontier models are Claude Opus 4.6 from Anthropic, Google’s Gemini 3.0 Pro, and OpenAI’s ChatGPT 5.2 Thinking. With all of the options, you get access to top-of-the-line AI models with a voice mode, the ability to see images and documents, the ability to execute code, good mobile apps, and the ability to create images and video (Claude lacks here, however). They all have different personalities and strengths and weaknesses, but for most people, just selecting the one they like best will suffice. For now, the other companies in this space have fallen behind, whether in models or in apps and harnesses, though some users may still have reasons for picking them.
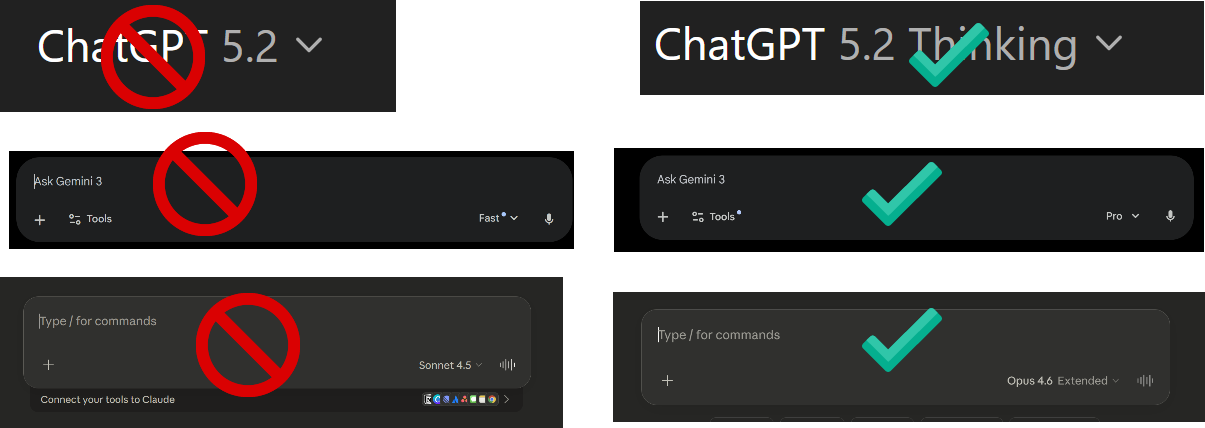
When you are using any AI app (more on those shortly), including phone apps or websites, the single most important thing you can do is pick the right model, which the AI companies do not make easy. If you are just chatting, the default models are fine, if you want to do real work, they are not. For ChatGPT, no matter whether you use the free or pay version, the default model you are given is “ChatGPT 5.2”. The issue is that GPT-5.2 is not one model, it is many, from the very weak GPT-5.2 mini to the very good GPT-5.2 Thinking to the extremely powerful GPT-5.2 Pro. When you select GPT-5.2, what you are really getting is “auto” mode, where the AI decides which model to use, often a less powerful one. By paying, you get to decide which model to use, and, to further complicate things, you can also select how hard the model “thinks” about the answer. For anything complex, I always manually select GPT-5.2 Thinking Extended (on the $20 plan) or GPT-5.2 Thinking Heavy (on more expensive plans). For a really hard problem that requires a lot of thinking, you can pick GPT-5.2 Pro, the strongest model, which is only available at a higher cost tier.
For Gemini, there are three options: Gemini 3 Flash, Gemini 3 Thinking, and, for some paid plans, 3 Pro. If you pay for the Ultra plan, you get access to Gemini Deep Think for very hard problems (which is in another menu entirely). Always pick Gemini 3 Pro or Thinking for any serious problem. For Claude, you need to pick Opus 4.6 (though the new Sonnet 4.6 is also powerful, it is not quite as good) and turn on the “extended thinking” switch.
Again, for most people, the model differences are now small enough that the app and harness matter more than the model. Which brings us to the bigger question.
The Chatbot Interfaces
The vast majority of people use chatbots, the main websites or mobile apps of ChatGPT, Claude, and Gemini, to access their AI models. In fact, we can call the chatbot the most important and widespread AI app. In the past few months, these apps have become quite different from each other.
Some of the differences are which features are bundled with AI:
Bundled into the Gemini chatbot (and accessible with the little plus button): you can access nano banana (the best current AI image creation tool), Veo 3.1 (a leading AI video creation tool), Guided Learning (when trying to study, this helps the AI act more like a tutor), and Deep Research
Bundled into ChatGPT is even more of a hodgepodge of options accessible with the plus button. You can Create Images (the image generator is almost as good as nano banana, but you can’t access the Sora video creator through the chatbot), Study and Learn (the equivalent to Guided Learning in Gemini, but there is also a separate Quizzes creator for some reason), Deep Research and Shopping Research (surprisingly good and overlooked), and a set of other options that most people will not use often, so I won’t cover here.
Claude has only Deep Research as bundled option, but you can access a study mode by creating a Project and selecting study project.
All of the AI models let you connect to data, such as letting the AI read your email and calendar, access your files, or connect to other applications. This can make AI far more useful, but, again, each AI tool has a different set of connectors you can use.
These are confusing! For most people doing real work, the most important additional feature is Deep Research and connecting AI to your content, but you may want to experiment with the others. Increasingly, however, what matters is the harness - the tools the AI has access to. And here, OpenAI and Anthropic have clear leads over Google. Both Claude.ai and ChatGPT have the ability to write and execute code, give you files, do extensive research, and a lot more. Google’s Gemini website is much less capable (even though its AI model is just as good),
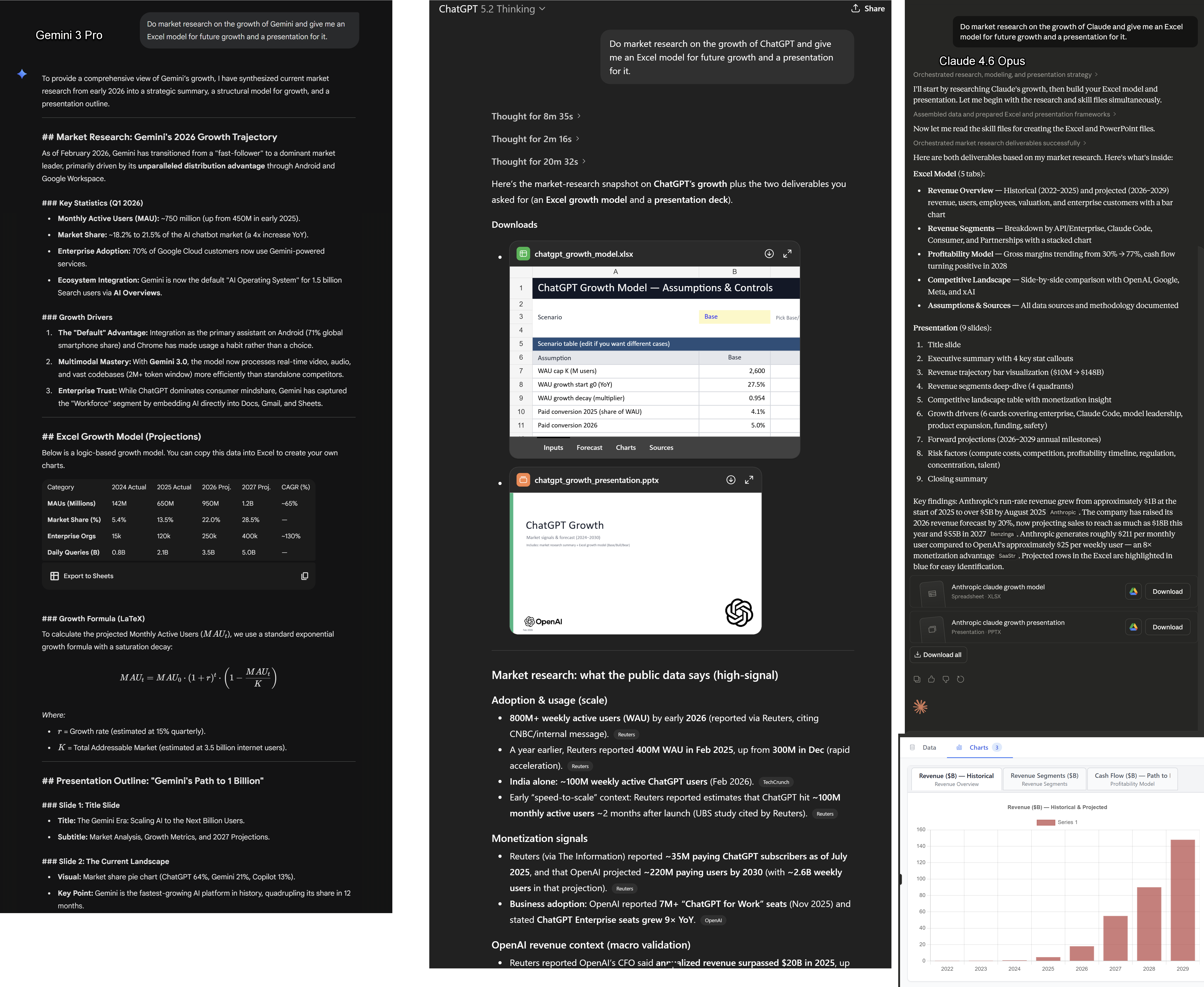
As you can see, asking a similar question gets working spreadsheets and PowerPoints from ChatGPT and Claude, along with clear citations I can follow up on. Gemini, however, is unable to produce either kind of document, and it does not provide citations or research. I do expect that Google will catch up here soon, however.
One final note on Chatbots. GPT-5.2 Pro, with the harness that comes with it, is a VERY smart model. It is the model that just helped derive a novel result in physics and it is the one I find most capable of doing complex statistical and analytical work. It is only accessible through more expensive plans. Google Gemini 3 Deep Think also seems very capable, but suffers from the same harness problem.

Other apps and harnesses
The chatbot websites are where most people interact with AI, but they are increasingly not where the most impressive work gets done. A growing set of other apps wrap these same models in more powerful harnesses, and they matter.
Claude Code, OpenAI Codex, and Google Antigravity are the most well-developed of these, and they are all aimed at coders. Each of them gives an AI model access to your codebase, a terminal, and the ability to write, run, and test code on its own. You describe what you want built and the AI goes and builds it, coming back when it’s done or stuck. If you write code for a living, these tools are changing your job. Because they have the most extensive harnesses, even if you don’t code, they can still do a tremendous amount.
For example, a couple years ago, I became interested in how you would make an entirely paper-based LLM by providing all of the original GPT-1’s internal weights and parameters (the code of the AI, listed as 117 million numbers) in a set of books. In theory, with enough time, you could use those numbers to do the math of an AI by hand. This seemed like a fun idea, but obviously not worth doing. A week ago, I asked Claude Code to just do it for me. Over the course of an hour or so (mostly the AI working, with a couple suggestions), it made 80 beautifully laid out volumes containing all of GPT-1, along with a guide to the math. It also came up with, and executed, covers for each volume that visualized the interior weights. It then put together a very elegant website (including the animation below), hooked it up to Stripe for payment and Lulu to print on demand, tested the whole thing, and launched it for me. I never touched or looked at any code. I had it make 20 books available at cost to see what happened - and sold out the same day. All of the volumes are still available as free PDFs on the site. Now, I can have a little project idea that would have required a lot of work, and just have it executed for me with very little effort on my part.
But the coding harnesses remain risky for amateurs and, obviously, focused on coding. New apps and harnesses are starting to focus on other types of knowledge work.
Claude for Excel and Powerpoint are examples of specific harnesses inside of applications. Both of them provide very impressive extensions to these programs. Claude for Excel, in particular, feels like a massive change in working with spreadsheets, with the potential for a similar impact to Claude Code for those who work with Excel for a living - you can, increasingly, tell the AI what you want to do and it acts a sort of junior analyst and does the work. Because the results are in Excel, they are easy to check. Google has some integration with Google Sheets (but not as deeply) and OpenAI does not really have an equivalent product.

Claude Cowork is something genuinely new, and it deserves its own category. Released by Anthropic in January, Cowork is essentially Claude Code for non-technical work. It runs on your desktop and can work directly with your local files and your browser. However, it is much more secure than Claude Code and less dangerous for non-technical users (it runs in a VM with default-deny networking and hard isolation baked in, for those who care about the details) You describe an outcome (organize these expense reports, pull data from these PDFs into a spreadsheet, draft a summary) and Claude makes a plan, breaks it into subtasks, and executes them on your computer while you watch (or don’t). It was built on the same agentic architecture as Claude Code, and was itself largely built by Claude Code in about two weeks. Neither OpenAI or Google have a direct equivalent, at least this week. Cowork is still a research preview, meaning it’s early and will eat through your usage limits fast, but it is a clear sign of where all of this is heading: AI that doesn’t just talk to you about your work, but does your work.
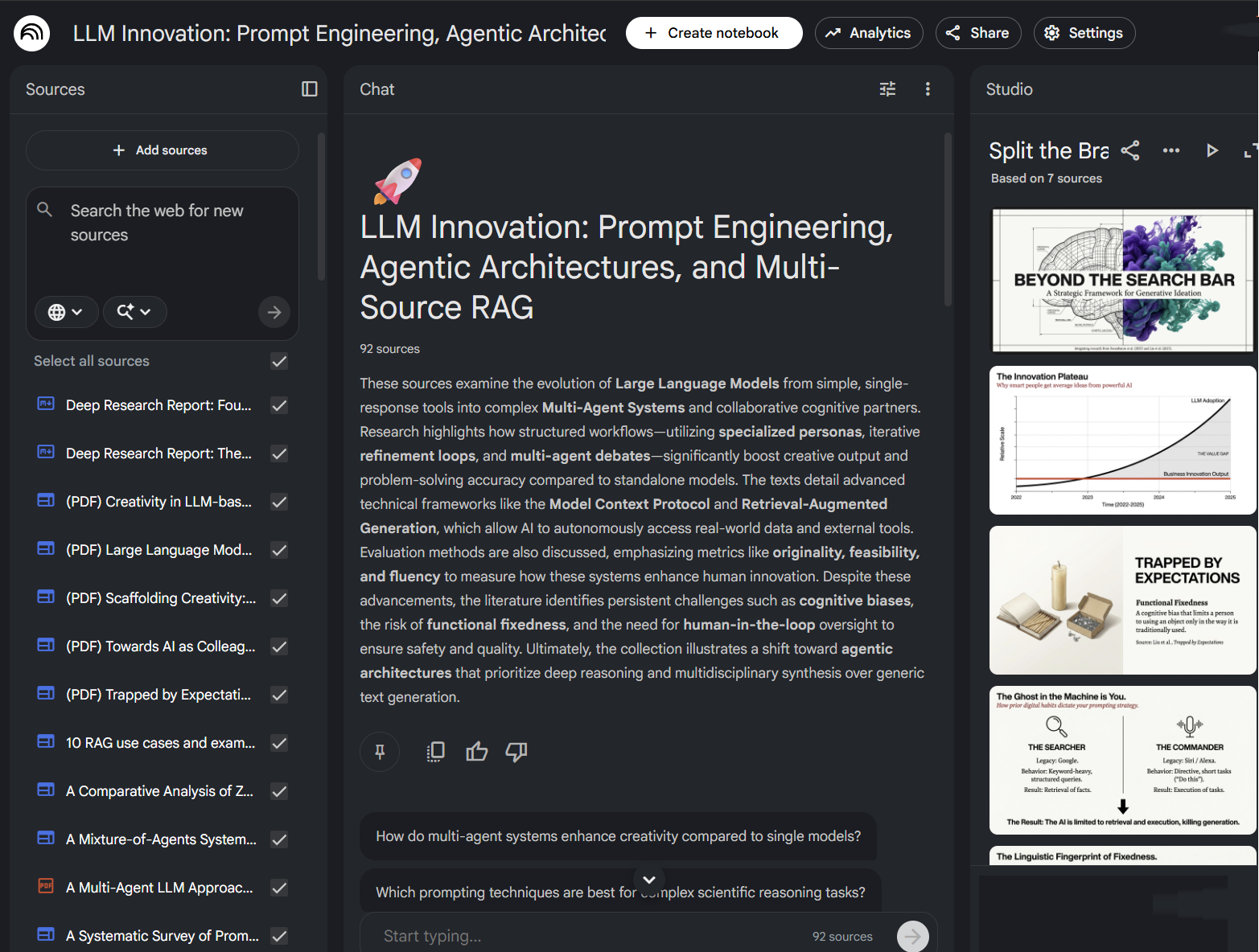
NotebookLM is Google’s answer to a different problem: how do you use AI to make sense of a lot of information? You can ask NotebookLM to do its own deep research, or else add in your own papers, YouTube videos, websites, or files, and NotebookLM builds an interactive knowledge base you can query, turn into slides, mind maps, videos and, most famously, AI-generated podcasts where two hosts discuss your material (you can even interrupt the hosts to ask questions). If you are a student, a researcher, or anyone who regularly needs to make sense of a pile of documents, NotebookLM is a very useful tool..
And then there is OpenClaw, which I want to mention even though it doesn’t fit neatly into any of these categories and which you almost definitely shouldn’t use. OpenClaw is an open-source AI agent that went viral in late January. It runs locally on your computer, connects to whatever AI model you want, and you talk to it like you were chatting with a person using standard chats like WhatsApp or iMessage. It can browse the web, manage your files, send emails, and run commands. It is sort of a 24/7 personal assistant that lives on your machine. It is also a serious security risk: you are giving an AI broad access to your computer and your accounts, and no one knows exactly what dangers you are exposing yourself to. But it does serve as a sign of where things are going.
What to do now
I know this is a lot. Let me simplify.
If you are just getting started, pick one of the three systems (ChatGPT, Claude, or Gemini), pay the $20, and select the advanced model. The advice from my book still holds: invite AI to everything you do. Start using it for real work. Upload a document you’re actually working on. Give the AI a very complex task in the form of an RFP or SOP. Have a back-and-forth conversation and push it. This alone will teach you more than any guide.
If you are already comfortable with chatbots, try the specific apps. NotebookLM is free and easy to use, which makes it a good starting place. If you want to go deeper, Anthropic offers the most powerful package in Claude Code, Claude Cowork (both accessible through Claude Desktop) as well as the specialized PowerPoint and Excel Plugins. Give them a try. Again, not as a demo, but with something you actually need done. Watch what it does. Steer it when it goes wrong. You aren’t prompting, you are (as I wrote in my last piece) managing.
The shift from chatbot to agent is the most important change in how people use AI since ChatGPT launched. It is still early, and these tools are still hard to figure out and will still do baffling things. But an AI that does things is fundamentally more useful than an AI that says things, and learning to use it that way is worth your time.

Sure, you made it work this time, but will it work next time?
Can you teach the method to someone else?
Do you have a protocol for what to do when it doesn’t work?
How can someone else contribute to your process to make it better?
Would you cross a bridge that was 99.7% safe? The answer is not necessarily simple. It depends on how many times you need to cross it (once, or every day for work), what happens if you fall (ankle sprain, or certain death), what happens if you do not cross it (mild inconvenience, or being chased by a tiger), and whether there is any alternative.
AI agent security faces the same question: what level of risk is acceptable, and who gets to decide?
There are two schools of thought, and they lead to very different conclusions about what we should build.
The Deterministic School
The first school says we must solve this problem deterministically. Simon Willison has been documenting the prompt injection problem for years1, and his conclusion remains sobering: we have known about this issue for more than two and a half years and we still do not have convincing mitigations. Models have no ability to reliably distinguish between instructions and data. Any content they process can be interpreted as an instruction.
Google’s CaMeL framework takes this seriously.2 It separates control flow from data flow, then enforces what may pass into each tool at execution time. A Privileged LLM sees only the trusted user request and writes the plan as code without ever seeing untrusted data. A Quarantined LLM parses untrusted content into structured fields and cannot call tools. Injected text cannot hijack tool execution directly.
Tested on AgentDojo, a benchmark of real-world agent tasks like managing emails and booking travel, CaMeL solved 77% of tasks with provable security, compared to 84% for an agent with no security at all. That is a big step forward. But that headline gap of seven percentage points hides the real cost: in complex task domains the drop is far steeper. The architectural constraints that provide security limit the autonomy users demand.
I explored this tension when analysing browser agents. The only reliable approach requires architectural boundaries that make certain attacks impossible rather than merely detectable. Do not tell the agent what not to do. Only give it options it can safely choose from. Make failure architecturally impossible. But an agent that can only choose from pre-approved options cannot handle novel situations. This is one reason why 95% of teams cannot ship their agents to production.
The Error Tolerance School
The second school says we must accept an error tolerance as a tradeoff. This is how we think about self-driving cars. Waymo reports more than a ten-fold reduction in crashes with serious injuries compared to human drivers.3 But it does not matter that they are ten times as safe. What matters is human perception, and we still have work to do convincing people that autonomous vehicles are safe despite what the stats say. We are in exactly the same place with AI agents.
The same logic applies. Humans fall for social engineering attacks constantly. Phishing works. If an AI agent falls for fewer attacks than a human assistant would, perhaps that is good enough. We do not demand perfection from human employees. We accept that people make mistakes, click wrong links, and occasionally leak sensitive information. This is the only way tools like OpenClaw will ever be considered “safe”: when we redefine “safe” as a relative term that includes tolerances. Not safe as in “cybersecurity”, but safe as in “bridge” or “driving in traffic”. The problem, as the comic above illustrates, is knowing what level of tolerance we will accept.
OpenAI has started framing prompt injection this way.4 Some critics say this downplays a technical flaw. But it also acknowledges a truth: we have been living with imperfect human security forever.
The Problem With Error Tolerance Today
The challenge is that red team researchers report it is still trivially easy to break through guardrails. Sander Schulhoff put it bluntly: bypassing guardrails is so easy that most people should not bother with them.5 A joint paper tested published defences against prompt injection with adaptive attacks and achieved above 90% attack success rate for most of them.6
This is not a matter of needing slightly better guardrails. The current approaches do not work. Attackers hide malicious instructions in images. They use social engineering techniques adapted from human manipulation. They chain together innocuous-seeming requests that combine into malicious actions. They use languages underrepresented in training data to bypass alignment mechanisms.
Security researcher Johann Rehberger tested Devin AI’s security and found it completely defenceless against prompt injection.7 All major providers have added guardrails, but none of them work against a determined attacker. I wrote about why independent coding agents are not ready partly because of these security gaps.
This is why I keep saying that error tolerance is not yet viable. The error rate is too high. When 90% of adaptive attacks succeed, you have no defence at all.
But Models Are Getting Better
Each new model generation shows dramatic improvement. On Gray Swan’s benchmark8, Opus 4.5 achieved a 4.7% attack success rate, compared to 12.6% for GPT-5.1 Thinking and 12.5% for Gemini 3 Pro. Anthropic’s own testing showed only 1.4% of prompt injection attacks succeeded against Opus 4.5, down from 10.8% for previous models with older safeguards.9 For computer use specifically, Opus 4.5 with extended thinking fully saturated Gray Swan’s benchmark, and even with 200 attempts most attackers failed to find a successful attack.
Today Anthropic released Opus 4.6, which they describe as having a safety profile “as good as, or better than, any other frontier model in the industry” with enhanced cybersecurity abilities and the lowest rate of over-refusals of any recent Claude model.10 The trend line is clear: each generation gets harder to attack.
This suggests the error tolerance school might eventually be right, even if it is wrong today. If models continue improving at this rate, we might reach a point where the residual attack success rate is low enough to accept as a tradeoff for usefulness. We do not demand that human assistants be immune to social engineering. If AI agents become more resistant than humans, perhaps that is sufficient.
What This Means For Practitioners
If you are building agent systems today, the numbers do not support relying on error tolerance. Use deterministic approaches where possible: constrain the action space, separate control and data flow, enforce policies at execution time, and accept the capability cost that comes with them. If you are building with agent loops, keep the tool set minimal and the permissions tight.
But watch the benchmarks, because if prompt injection resistance continues improving, the calculus changes. A system with a 1% attack success rate faces very different risk tradeoffs than one with 90%, and the architectural constraints that feel necessary today might become optional overhead tomorrow. Early autonomous vehicles could only work in specific cities with detailed maps in good weather, but as the technology improved those constraints relaxed. The same pattern might apply to AI agents.
For now, I remain in the deterministic school because the error rates are too high and the attacks too easy. I uninstalled OpenClaw for exactly this reason. But I am watching each new model’s benchmark results closely, and if the next generation cuts attack success rates by another order of magnitude, error tolerance starts looking viable. Guardrails do not work today, and whether they work tomorrow depends on whether model capability improvements outpace attacker sophistication.
Thanks to Ville Hellman and Dave Cunningham for conversations that shaped this post.
-
Simon Willison has been the most consistent voice documenting prompt injection risks. His November 2025 post reviews key research papers including “Agents Rule of Two” from Meta and the adaptive attacks paper from OpenAI, Anthropic, and Google DeepMind. ↩
-
Google’s CaMeL (Capabilities for Machine Learning) framework is explained in detail in Willison’s analysis. The key insight is separating the LLM that plans from the LLM that processes untrusted data. ↩
-
Waymo published their safety data in December 2025, showing significant reductions in serious injury crashes compared to human drivers across their operational domains. ↩
-
OpenAI’s Atlas browser announcement explicitly compares prompt injection to online fraud, framing it as an ongoing arms race rather than a solvable technical problem. ↩
-
Sander Schulhoff discussed AI security on Lenny’s Podcast. Schulhoff runs HackAPrompt, the largest AI red teaming competition, in partnership with OpenAI. ↩
-
The adaptive attacks paper tested 12 published defences and achieved above 90% attack success rates against most of them by tuning general optimisation techniques. The research included authors from OpenAI, Anthropic, and Google DeepMind. ↩
-
Johann Rehberger spent $500 on Devin AI security testing and found the agent could be manipulated to expose ports, leak access tokens, and install command-and-control malware. ↩
-
Gray Swan’s independent benchmark for prompt injection resistance. See Zvi’s analysis of Opus 4.5’s performance, which shows a significant gap between Anthropic’s model and competitors. ↩
-
Anthropic’s model card for Opus 4.5 includes detailed safety evaluations including prompt injection resistance metrics. ↩
-
Anthropic’s Opus 4.6 announcement describes the model’s safety profile and enhanced cybersecurity abilities. The system card includes their most comprehensive set of safety evaluations to date. ↩
Next Page of Stories